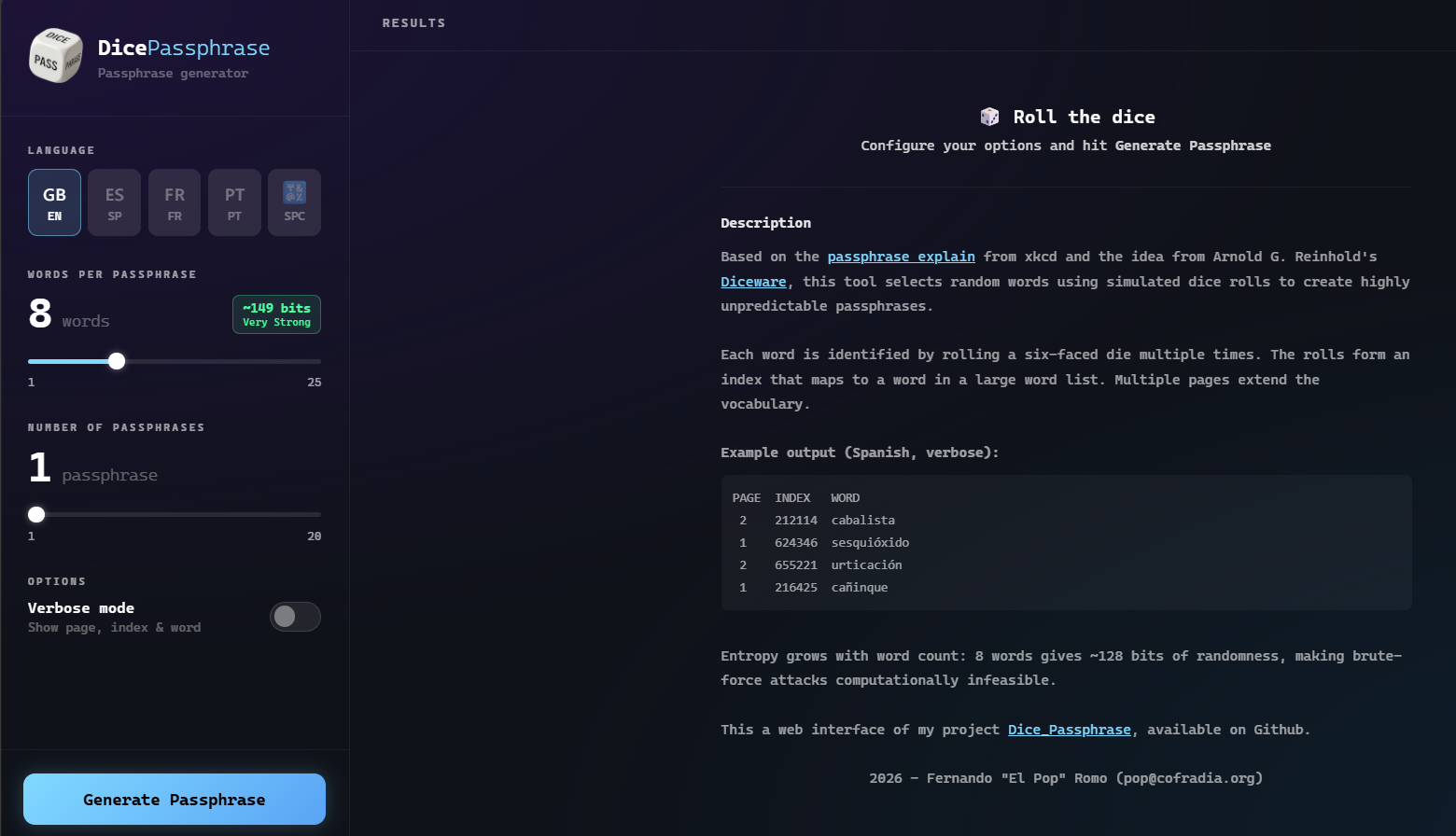
La nueva vulnerabilidad de la IA: datos basura
Autor: Daniel Orduna
Actualizado: 11/5/2025 5:29:06 PM horas
Un grupo de investigadores de Texas A&M University, University of Texas at Austin y Purdue University descubrió que los modelos de lenguaje (LLM) pueden deteriorarse al exponerse repetidamente a datos basura: información viral, imprecisa o de baja calidad que circula en internet.
El fenómeno, descrito como “brain rot” (pudrición cerebral), provoca que los modelos pierdan coherencia, razonamiento y precisión con el tiempo. Según los autores, este efecto no solo limita el desempeño técnico, sino que también puede distorsionar la forma en que los modelos interpretan la realidad.
“Entrenar un modelo con desinformación es como alimentar un cerebro con comida chatarra”, explican los investigadores en el portal del proyecto LLMs Can Get Brain Rot! (2025).
Otro hallazgo relevante proviene de Anthropic, en colaboración con el Alan Turing Institute y el UK AI Safety Institute, titulado, Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples (2025), demuestra que basta con aproximadamente 250 documentos maliciosos para alterar el comportamiento de un modelo de lenguaje grande, sin importar su tamaño (desde 600 M hasta 13 B de parámetros).
Esto significa que un atacante no necesita controlar miles o millones de datos, como se pensaba antes, para modificar la conducta de un sistema. Con un número reducido de archivos envenenados, puede inducir errores, sesgos o incluso puertas traseras (backdoors) difíciles de detectar.
El hallazgo plantea nuevos desafíos en materia de seguridad y gobernanza de datos, pues evidencia que pequeñas filtraciones pueden generar impactos desproporcionados.
Ambos estudios llegan a la misma conclusión: la inteligencia artificial es tan confiable como los datos que la alimentan. Si el contenido de entrenamiento está contaminado, los resultados lo estarán también. Por eso, las organizaciones que trabajan con IA deben invertir en:
✅ Verificación y curación de fuentes.
✅ Auditorías periódicas de entrenamiento.
✅ Filtros de calidad y sesgo en datos recolectados.
✅ Supervisión humana en los procesos de aprendizaje automático.
En Execudata, creemos que la ciberseguridad empieza con la información. La defensa más eficaz no siempre está en el código, sino en la pureza del conocimiento que lo nutre.